【自分の声TTS×Claude Code×FFmpeg】画面録画を放り込むだけで"自分の声"で解説するショート動画を作ってみた
tantan_tech
改善紀

2025年3月、私はやったことのない業務を任されました。機械学習モデルの作成です。
「Pythonって何ができるの?」「どうやったら自分のPCでPythonが動くの?」「機械学習って何?」
そんなレベルからのスタートでした。土木現場の施工管理を5年経験し、DX推進に1.5年携わってきた私にとって、プログラミングは完全に未知の領域でした。
機械学習モデルそのものは全てPythonで書いているわけではありません。AutoMLにデータを投入して、モデル構築はツールに任せています。ただ投入するためのデータ前処理はPythonで実行する必要がありました。
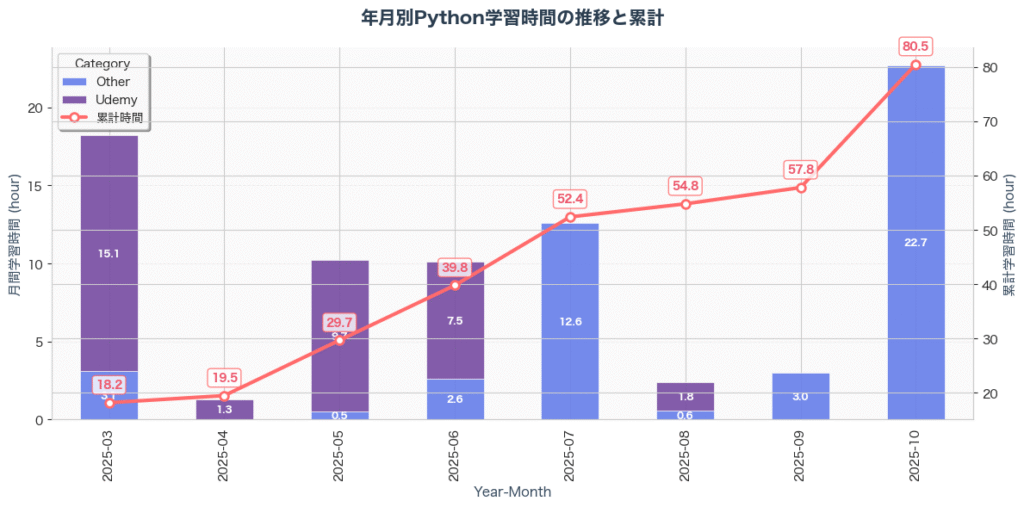
初めてPythonを触ってから7ヶ月後。プライベートで累計80.5時間の学習を経て、私は実務でデータ前処理をPythonで行えるようになっていました。この記事は、非IT人材がPythonを学び、生成AIの力を借りながら実務レベルに到達するまでの、リアルな記録です。
私がデータに興味を持ったきっかけは、DX推進時代にさかのぼります。
現場に自分が展開したシステムが本当に使われているか、データでシビアに見たいと思って、Power BIに手を出しました。
データを可視化する面白さ、数字から現場の実態が浮かび上がる瞬間の快感。これを味わってから、私は「もっとデータと向き合いたい」と強く思うようになりました。
そしてIT企画部門へ希望に出して異動をしました。データ利活用という新たなフィールドへ踏み出すことになります。そして2025年3月、機械学習という未知の領域に挑戦することになりました。
最初の1ヶ月は、ほぼUdemyでの基礎学習に費やしました。
受講したコースと所要時間
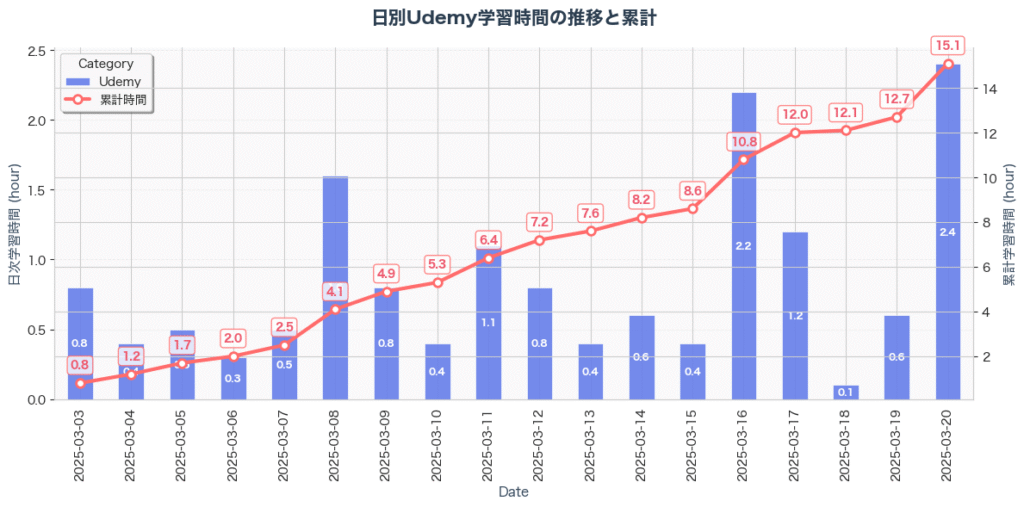
変数、ループ、関数、条件分岐……プログラミングの基本文法を一つずつ学んでいきます。講座の動画を見て、手を動かして、演習問題を解く。
だが、すぐに壁にぶつかりました。
「なんかこんなのがあった気がするけど、思い出せない」 「書いてもエラーが出まくる」
特に厄介だったのはループです。for文とwhile文、インデックスとイテレータ、range()の使い方……正直に言うと、今でも完全に理解しているとは言えません笑
「なんかそんなのあったな〜」となったぐらいです笑
5月に入ると、状況が一変しました。機械学習モデル作成プロジェクトが本格的に始まったのです。
なぜExcelではなくPythonで前処理を実行する必要があるのか。それは使用するデータ数と、再現性に尽きると思います。1つのデータに対して整形をすればいいとか、1回だけやればいいとかであればExcelでもどうにかなります。ただ、それが10ぐらいのデータを相手にして、こっちのデータとこっちのデータをくっつけて、条件で絞り込みして、新しい列を作成してとなるとそうはいきません。さらに元データ更新時に同じ処理ができるような再現性も必要なので、Pythonで処理を実行する必要があります。
データの前処理とは主にこんな感じです。
これら全てをPythonで行う必要がありました。
ここで私は、ある決断をしました。
「実務時間はフル生成AIで書く」
Udemy的な正攻法の学習を続けながら実務をこなすのは、時間的に無理でした。一個一個調べて手で書いているようでは、到底間に合わないしやってられない!!
実務では徹底的に生成AIを活用しました。
「いい時代だな〜」としみじみと思いました笑
生成AIに投げる際は、Udemyでの基礎学習がかなり役に立ちました。なんかこういうことをしたい、というなんかこういうことがわかっているからです。生成AIは強力なツールですが、扱う人間のスキルが高いことに越したことはないと実感しました。
【AIに投入する情報】
この方法で、9割以上のコードは動くようになりました。
正直、この時期のコードはほぼ理解していませんでした。
df_train['age'].fillna(df_train['age'].median(), inplace=True)たとえばこんなコード。今でもちょっと考えないと何しているのか理解できません笑
しかし、コードを理解していなくても、コードを実行した結果が合っているかどうかは確認することができます。
.shape、.head()、.info()、.columnsといったメソッドを適宜使って、データの形や中身をチェックしました。期待通りの結果になっていればOKという感じです。
「これでいいのか?」という不安感はありましたが、締め切りは待ってくれません。まずは動くものを作る。理解は後からついてくる、と自分に言い聞かせました。
そして実際、その判断は正しかったです。
8月頃、私はGitHub Copilotの存在を知りました。
VS Code内でコードの続きを自動補完してくれるこのツールを、まずプライベートで試してみました。すると、これが驚くほど便利だったのです。(即、課金しました笑)
そこで9月、試験的に会社でも使えるように上申しました。結果、承認。これにより、私は生成AI二刀流となりました。
【私の生成AI使い分け】
この二刀流により、コーディング速度が格段に上がりました。GitHub Copilotは「隣でアドバイスしてくれる先輩エンジニア」のような存在で、書きたいコードをほぼリアルタイムで提案してくれます。
色々あり一旦完成しました。Pythonもかなり丁寧にわかりやすく書くことを意識したので、後任者への引き継ぎもスムーズにできると期待しています。機械学習モデル作成において、Pythonでのデータ前処理は確かに重要ですが、それ以上に重要なことが他に山ほどあります。なので、最低限の知識を身につけたら、あとは生成AIの補助を受けて楽をして良かったです。せっかく苦労してコードを書いても、やっぱりいらないってなった時のダメージが少ないですしね。早く成果を出して、早く失敗することがプロジェクト成功に必要みたいです。
振り返ると、この7ヶ月間、生成AIなしでは絶対に乗り越えられませんでした。
1. コード生成マシンとして(ChatGPT)
「こういうことをしたい」→「コードを書いてもらう」→「動かす」→「エラーが出たら投げる」 複雑な処理はこのパターンです。
2. リアルタイム補完として(GitHub Copilot)
コードを書きながら、次に書くべき処理を提案してもらう。 実務の9割はこれで回せました。
3. エラー解決の先生として
自分で書いたコードがエラーを吐いたとき、エラーメッセージを丸ごと投げると、原因と修正案を教えてくれます。Stack Overflowを検索する時間が劇的に減りました。
4. 概念理解の対話相手として
「そもそも機械学習って何?」「過学習ってどういうこと?」みたいな概念的な質問に、分かりやすく答えてくれます。技術書を読むより速いです。
5. 愚痴を言う相手として?
24時間365日どんな話でも聞いてくれます。新しい領域の業務でのモヤモヤや悩みも生成AIは受け止めてくれます。悩んだら相談もしてみましょう(なんでも肯定してくれるので、鵜呑みにしすぎないように笑)
もちろん、全てをAI任せにするのは危険です。
AIが生成したコードが何をしているか、最低限の理解は必要でした。じゃないと、エラーが出たときに何を修正すればいいか分かりません。
私が心がけたのは、「だいたい理解」です。完璧に理解しようとすると、時間がいくらあっても足りません。でも、コードの大まかな流れと、各行が何をしているかが分かれば、実務では十分でした。
7ヶ月間Pythonを学んで、私が得た最大の財産は「データの解像度が上がった」ことです。
Power BIは強力なツールです。直感的な操作でデータを可視化できます。でも、Power BIでできることには限界があります。
Pythonを学んだことで、「データの裏側」が見えるようになりました。
データがどんな形式で保存されているのか。欠損値や異常値がどれくらいあるのか。変数同士の関係性はどうなっているのか。
こうした「データの実態」を把握できるようになったことで、Power BIでの可視化もより深いものになりました。
Pythonの前提知識があることで、Microsoft Fabricのエコシステム全体を少し使いこなせるようになったのも大きな収穫です。
【Fabricでの一気通貫フロー例】
このように、データ収集から加工、分析、可視化まで、一貫した設計ができるようになりました。
特にNotebookでのPython処理は、Power Queryでは不可能だった複雑な加工や、AIを使った高度な処理を可能にします。これは、Pythonを学んでいなければ辿り着けなかった領域です。
私は今、市民開発推進チームに所属しています。Power Platformを使って、現場の業務を効率化するためのツールを作る支援をしています。
ここでも、Pythonの知識が活きています。
【業務ツールの使い分け】
Pythonは「Excel/Power Platformでは難しいけど、専門システムを作るほどでもない」という中間領域で威力を発揮します。
たとえば、「1万行を超えるデータの複雑な集計」「複数のCSVファイルを自動で結合」「簡易的な予測モデルの作成」といった処理は、Pythonの得意分野です。
現在、私は市民開発推進の仕事をしています。そこで強く感じるのは、「市民開発者にこそPythonを学んでほしい」ということです。
Power AppsやPower Automateを作るとき、結局のところデータを扱います。データの構造を理解していないと、効率的なアプリは作れません。
Pythonでデータを触った経験があると、「このデータはこういう構造になっているはずだ」という感覚が身につきます。
Power Platformは万能ではありません。複雑な処理や大量データの処理には向いていません。
そんなとき、Pythonで前処理をしてからPower Platformに渡す、という使い方ができます。市民開発の可能性が一気に広がります。
Microsoft Fabricは、データ基盤、分析、可視化を統合した強力なプラットフォームです。しかし、その真価を発揮するには、NotebookでのPython処理が不可欠です。
Pythonができることで、Power PlatformとFabricを組み合わせた、より高度なソリューションを設計できるようになります。
「こういうツールが欲しいけど、Power Platformじゃ無理かな……」
そう思っていたものが、Pythonを学ぶことで「作れるかもしれない」に変わります。選択肢が増えることは、それだけで大きな価値があります。
Q1. プログラミング完全初心者でも本当にできますか?
A. できるかどうかというよりも、「できるまでやる」が正しいかもしれません。そのできた状態が自力100%ではなく、自力70%・生成AI30%という形でもいいと思います。ただし、自ら勉強して習得しようという意思や行動は必須です。どこまで行っても生成AIは補助にすぎません。とはいえ、生成AIがある今の時代は、昔と比べてだいぶ挫折しづらいと思います。一緒に頑張りましょう!
Q2. GitHub Copilotは必須ですか?
A. 必須ではありませんが、あるとスピードが格段に上がります。ChatGPTだけでも十分実務は回せますが、Copilotがあるとリアルタイムで補完してくれるので効率が全然違います。(あとストレスが減ります笑)
Q3. Udemyの講座は最後まで完走する必要がありますか?
A. 完走しなくても大丈夫です。基本文法(変数、if文、for文、関数、リスト)を「こんなのがあるんだな」程度に理解したら、実務で手を動かす方が身につきます。私もループは今でも完全には理解していません笑
Q4. 生成AIにコードを書かせる時のコツはありますか?
A. 生成AIを使う際の基本的な留意事項を抑えることと、具体的な情報を渡すことです。「やりたいこと」「実行環境」「データフレーム名」「カラム名」を明確に伝えれば、9割以上のコードは動きます。エラーが出たら、エラーメッセージを全文コピペして投げ直せばOKです。
Q5. ExcelやPower Queryではダメなんですか? Pythonを学ぶ必要性は?
A. ExcelやPower Queryは便利ですが、扱えるデータ件数に限界があります。また、複数のデータを結合したり、複雑な条件分岐や繰り返し処理、機械学習向けの高度なデータ処理はPythonでないと厳しいです。さらに、処理の再現性(同じ処理を何度も実行できる)もPythonの大きな強みです。また、Microsoft FabricのNotebookを使った一気通貫のデータ処理が可能になります。






